
| 12:31
|
No Comments
lambda architecture définition et exemples
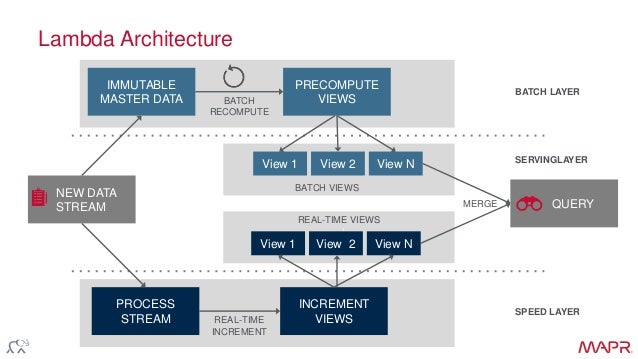
l'architecture Lambda est une architecture de traitement de données conçu pour traiter des quantités massives de données en tirant parti des deux méthodes de documents et de traitement de flux. Cette approche de l'architecture tente d'équilibrer la latence, le débit et la tolérance aux pannes en utilisant le traitement par lots pour fournir des vues complètes et précises de données par lots, tout en utilisant simultanément le traitement des flux en temps réel pour fournir des vues de données en ligne. Les deux sorties de vue peuvent être joints avant la présentation. La montée de l'architecture lambda est en corrélation avec la croissance des grandes données, analyses en temps réel, et la volonté de réduire les latences de MapReduce.
l'architecture Lambda décrit un système composé de trois couches: le traitement par lots, la vitesse (ou en temps réel) de traitement, et une couche de service pour répondre aux questions:. Les couches de traitement ingèrent à partir d'une copie maître immuable de l'ensemble des données .
- Batch Layer
- Speed Layer
- Serving Layer






")